
Die unheimliche Seite von KI: Eine experimentelle Untersuchung zu kognitiven Verzerrungen in der Wahrnehmung von ChatGPTs Theory-of-Mind Fähigkeiten
von Tobias Senger (2024)
Einleitung
Durch die Fortschritte in der Künstlichen Intelligenz (KI), die zunehmend menschenähnliche Fähigkeiten zeigen kann, schreiben Menschen KI-Systemen häufig mentale Zustände und einen Geist zu. In dieser Untersuchung wird erforscht, ob Menschen dem Chatbot ChatGPT eine Theory-of-Mind (ToM) zuschreiben und wann diese Fähigkeit als unheimlich betrachtet wird. Unter Verwendung der Mind Perception Theorie und des Uncanny Valley Phänomens wurden kognitive Verzerrungen in der menschlichen Wahrnehmung von ChatGPTs Fähigkeiten erforscht.
Methodik
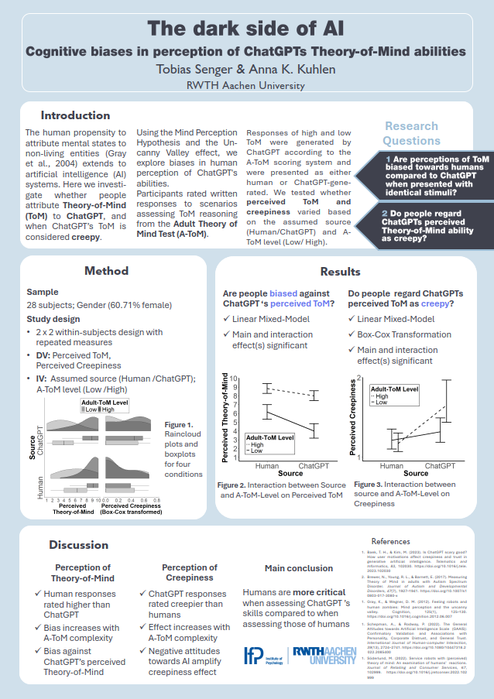
In einer Online-Untersuchung bewerteten 28 Teilnehmende (62% weiblich) schriftliche Antworten zu Aufgaben des
Adult-Theory-of-Mind Tests (A-ToM). Antworten mit hohen und niedrigem A-ToM-Fähigkeiten, generiert durch ChatGPT gemäß dem A-ToM Scoring-System, wurden entweder als von einem Menschen oder ChatGPT erstellt präsentiert. Es wurde getestet, ob wahrgenommene ToM-Fähigkeiten und wahrgenommene Unheimlichkeit basierend auf der attribuierten Urheberschaft (Mensch vs. ChatGPT) und dem A-ToM-Level (Niedrig vs. Hoch) variierten.
Ergebnisse
ChatGPT wurden geringere ToM-Fähigkeiten zugeschrieben als den (vermeintlichen) Menschen, sowohl beim Vergleich der Antworten mit hohem A-ToM-Level, als auch beim Vergleich der weniger komplexen Antworten miteinander, was auf einen expliziten Bias zum Nachteil von ChatGPT hinweist.
Konsistent mit der Mind Perception Theorie wurden ChatGPT-Antworten mit hohem A-ToM-Level als unheimlicher bewertet im Vergleich zu ChatGPT-Antworten mit niedrigem A-ToM-Level und im Vergleich zu menschlichen Antworten unabhängig des A-ToM-Levels.
Negative allgemeine Einstellungen gegenüber KI verstärkten die wahrgenommene Unheimlichkeit, wenn die Antworten als von ChatGPT generiert gekennzeichnet waren.
Die Erkenntnisse deuten darauf hin, dass Menschen kritischer sind, wenn sie ChatGPTs Fähigkeiten bewerten, verglichen mit der Bewertung der Fähigkeiten eines Menschen.
Tagung experimentell arbeitender Psychologen (TeaP 2024, 66th Conference)
The uncanny side of AI: Cognitive biases in perception of ChatGPT's Theory-of-Mind abilities
Tobias Senger (2024)
Due to advances in artificial intelligence (AI), which can increasingly demonstrate human-like abilities, people often attribute mental states and a mind to AI systems. Here we investigate whether people attribute Theory-of-Mind (ToM) abilities to ChatGPT, and when ChatGPT’s ToM ability is considered creepy. Using the Mind-Perception Hypothesis and the Uncanny Valley phenomenon, we explore biases in human perception of ChatGPT's abilities.
In an online study, 28 participants (62% female) rated written responses to scenarios assessing ToM reasoning from the Adult Theory of Mind Test (A-ToM). Responses of high and medium ToM abilities were generated by ChatGPT according to the A-ToM scoring system, and were presented as either human or ChatGPT-generated. We tested whether perceived ToM abilities and perceived creepiness varied based on the assumed authorship (Human vs. ChatGPT) and A-ToM level (Low vs. High).
The results showed that lower ToM abilities were attributed to ChatGPT than to supposed humans, when comparing high A-ToM-level responses and when comparing less complex responses, indicating an explicit bias against ChatGPT. Consistent with the Mind Perception Theory, high A-ToM-level ChatGPT responses were rated as creepier compared to low A-ToM-level ChatGPT responses and to human responses regardless of A-ToM level. It was also found that negative general attitudes toward AI increased the perceived creepiness when responses were labeled as generated by ChatGPT.
These findings suggest that people are more critical when assessing ChatGPT's skills compared to when assessing those of humans.